 |
Large language models replicate and predict human
cooperation across experiments in game theory
Andrea Cera Palatsi, Samuel Martin-Gutierrez, Ana S. Cardenal &
Max Pellert
arXiv:2511.04500 (2025)
[abs]
[cite]
[bibtex]
[link] [code]
Palatsi, A. C., Martin-Gutierrez, S., Cardenal, A. S.,
& Pellert, M. (2025). Large language models
replicate and predict human cooperation across
experiments in game theory (arXiv:2511.04500). arXiv. https://doi.org/10.48550/arXiv.2511.04500
@misc{palatsiLargeLanguageModels2025, title =
{Large Language Models Replicate and Predict Human Cooperation across
Experiments in Game Theory}, author = {Palatsi, Andrea Cera and
{Martin-Gutierrez}, Samuel and Cardenal, Ana S. and Pellert, Max}, year
= {2025}, month = nov, number = {arXiv:2511.04500}, eprint =
{2511.04500}, primaryclass = {cs}, publisher = {arXiv}, doi =
{10.48550/arXiv.2511.04500}, urldate = {2025-11-07}, abstract = {Large
language models (LLMs) are increasingly used both to make decisions in
domains such as health, education and law, and to simulate human
behavior. Yet how closely LLMs mirror actual human decision-making
remains poorly understood. This gap is critical: misalignment could
produce harmful outcomes in practical applications, while failure to
replicate human behavior renders LLMs ineffective for social
simulations. Here, we address this gap by developing a digital twin of
game-theoretic experiments and introducing a systematic prompting and
probing framework for machine-behavioral evaluation. Testing three
open-source models (Llama, Mistral and Qwen), we find that Llama
reproduces human cooperation patterns with high fidelity, capturing
human deviations from rational choice theory, while Qwen aligns closely
with Nash equilibrium predictions. Notably, we achieved population-level
behavioral replication without persona-based prompting, simplifying the
simulation process. Extending beyond the original human-tested games, we
generate and preregister testable hypotheses for novel game
configurations outside the original parameter grid. Our findings
demonstrate that appropriately calibrated LLMs can replicate aggregate
human behavioral patterns and enable systematic exploration of
unexplored experimental spaces, offering a complementary approach to
traditional research in the social and behavioral sciences that
generates new empirical predictions about human social
decision-making.}, archiveprefix = {arXiv}, keywords = {Computer Science
- Artificial Intelligence,Computer Science - Computation and
Language,Computer Science - Computer Science and Game Theory,Computer
Science - Multiagent Systems}
} Copy to Clipboard
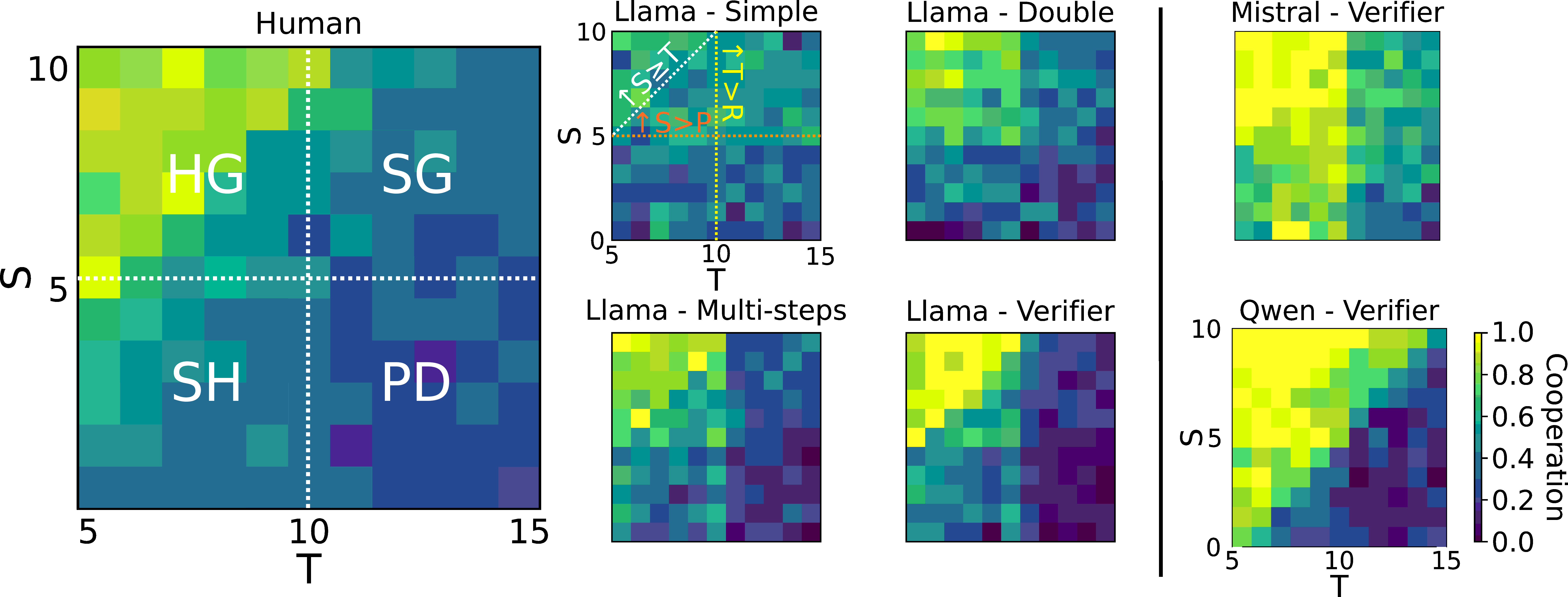
Large language models (LLMs) are increasingly used both to
make decisions in domains such as health, education and law, and
to simulate human behavior. Yet how closely LLMs mirror actual
human decision-making remains poorly understood. This gap is
critical: misalignment could produce harmful outcomes in
practical applications, while failure to replicate human
behavior renders LLMs ineffective for social simulations. Here,
we address this gap by developing a digital twin of
game-theoretic experiments and introducing a systematic
prompting and probing framework for machine-behavioral
evaluation. Testing three open-source models (Llama, Mistral and
Qwen), we find that Llama reproduces human cooperation patterns
with high fidelity, capturing human deviations from rational
choice theory, while Qwen aligns closely with Nash equilibrium
predictions. Notably, we achieved population-level behavioral
replication without persona-based prompting, simplifying the
simulation process. Extending beyond the original human-tested
games, we generate and preregister testable hypotheses for novel
game configurations outside the original parameter grid. Our
findings demonstrate that appropriately calibrated LLMs can
replicate aggregate human behavioral patterns and enable
systematic exploration of unexplored experimental spaces,
offering a complementary approach to traditional research in the
social and behavioral sciences that generates new empirical
predictions about human social decision-making.
|
 |
Neural network embeddings recover value dimensions from
psychometric survey items on par with human data
Max Pellert, Clemens M. Lechner, Indira Sen & Markus
Strohmaier
arXiv:2509.24906 (accepted at EACL 2026) (2025)
[abs]
[cite]
[bibtex]
[link] [code]
Pellert, M., Lechner, C. M., Sen, I., & Strohmaier,
M. (2025). Neural network embeddings recover value
dimensions from psychometric survey items on par with
human data (arXiv:2509.24906). arXiv. https://doi.org/10.48550/arXiv.2509.24906
@misc{pellertNeuralNetworkEmbeddings2025, title
= {Neural Network Embeddings Recover Value Dimensions from Psychometric
Survey Items on Par with Human Data}, author = {Pellert, Max and
Lechner, Clemens M. and Sen, Indira and Strohmaier, Markus}, year =
{2025}, month = sep, number = {arXiv:2509.24906}, eprint = {2509.24906},
primaryclass = {cs}, publisher = {arXiv}, doi =
{10.48550/arXiv.2509.24906}, urldate = {2025-09-30}, abstract = {This
study introduces “Survey and Questionnaire Item Embeddings
Differentials” (SQuID), a novel methodological approach that enables
neural network embeddings to effectively recover latent dimensions from
psychometric survey items. We demonstrate that embeddings derived from
large language models, when processed with SQuID, can recover the
structure of human values obtained from human rater judgments on the
Revised Portrait Value Questionnaire (PVQ-RR). Our experimental
validation compares multiple embedding models across a number of
evaluation metrics. Unlike previous approaches, SQuID successfully
addresses the challenge of obtaining negative correlations between
dimensions without requiring domain-specific fine-tuning. Quantitative
analysis reveals that our embedding-based approach explains 55% of
variance in dimension-dimension similarities compared to human data.
Multidimensional scaling configurations from both types of data show
fair factor congruence coefficients and largely follow the underlying
theory. These results demonstrate that semantic embeddings can
effectively replicate psychometric structures previously established
through extensive human surveys. The approach offers substantial
advantages in cost, scalability and flexibility while maintaining
comparable quality to traditional methods. Our findings have significant
implications for psychometrics and social science research, providing a
complementary methodology that could expand the scope of human behavior
and experience represented in measurement tools.}, archiveprefix =
{arXiv}, keywords = {Computer Science - Artificial Intelligence,Computer
Science - Computation and Language}
} Copy to Clipboard
This study introduces “Survey and Questionnaire Item
Embeddings Differentials” (SQuID), a novel methodological
approach that enables neural network embeddings to effectively
recover latent dimensions from psychometric survey items. We
demonstrate that embeddings derived from large language models,
when processed with SQuID, can recover the structure of human
values obtained from human rater judgments on the Revised
Portrait Value Questionnaire (PVQ-RR). Our experimental
validation compares multiple embedding models across a number of
evaluation metrics. Unlike previous approaches, SQuID
successfully addresses the challenge of obtaining negative
correlations between dimensions without requiring
domain-specific fine-tuning. Quantitative analysis reveals that
our embedding-based approach explains 55% of variance in
dimension-dimension similarities compared to human data.
Multidimensional scaling configurations from both types of data
show fair factor congruence coefficients and largely follow the
underlying theory. These results demonstrate that semantic
embeddings can effectively replicate psychometric structures
previously established through extensive human surveys. The
approach offers substantial advantages in cost, scalability and
flexibility while maintaining comparable quality to traditional
methods. Our findings have significant implications for
psychometrics and social science research, providing a
complementary methodology that could expand the scope of human
behavior and experience represented in measurement tools.
|
 |
Only a Little to the Left: A Theory-grounded Measure of
Political Bias in Large Language Models
Mats Faulborn, Indira Sen, Max Pellert, Andreas Spitz & David
Garcia
Proceedings of the 63rd Annual Meeting of the Association for
Computational Linguistics (Volume 1: Long Papers) (2025)
[abs]
[cite]
[bibtex]
[link] [code]
Faulborn, M., Sen, I., Pellert, M., Spitz, A., &
Garcia, D. (2025). Only a Little to the Left: A
Theory-grounded Measure of Political Bias in Large
Language Models. In W. Che, J. Nabende, E. Shutova,
& M. T. Pilehvar (Eds.), Proceedings of the 63rd
Annual Meeting of the Association for Computational
Linguistics (Volume 1: Long Papers) (pp. 31684–31704).
Association for Computational Linguistics. https://aclanthology.org/2025.acl-long.1529/
@inproceedings{faulbornOnlyLittleLeft2025a,
title = {Only a {{Little}} to the {{Left}}: {{A Theory-grounded
Measure}} of {{Political Bias}} in {{Large Language Models}}}, booktitle
= {Proceedings of the 63rd {{Annual Meeting}} of the {{Association}} for
{{Computational Linguistics}} ({{Volume}} 1: {{Long Papers}})}, author =
{Faulborn, Mats and Sen, Indira and Pellert, Max and Spitz, Andreas and
Garcia, David}, editor = {Che, Wanxiang and Nabende, Joyce and Shutova,
Ekaterina and Pilehvar, Mohammad Taher}, year = {2025}, month = jul,
pages = {31684–31704}, publisher = {Association for Computational
Linguistics}, address = {Vienna, Austria}, abstract = {Prompt-based
language models like GPT4 and LLaMa have been used for a wide variety of
use cases such as simulating agents, searching for information, or for
content analysis. For all of these applications and others, political
biases in these models can affect their performance. Several researchers
have attempted to study political bias in language models using
evaluation suites based on surveys, such as the Political Compass Test
(PCT), often finding a particular leaning favored by these models.
However, there is some variation in the exact prompting techniques,
leading to diverging findings, and most research relies on
constrained-answer settings to extract model responses. Moreover, the
Political Compass Test is not a scientifically valid survey instrument.
In this work, we contribute a political bias measured informed by
political science theory, building on survey design principles to test a
wide variety of input prompts, while taking into account prompt
sensitivity. We then prompt 11 different open and commercial models,
differentiating between instruction-tuned and non-instruction-tuned
models, and automatically classify their political stances from 88,110
responses. Leveraging this dataset, we compute political bias profiles
across different prompt variations and find that while PCT exaggerates
bias in certain models like GPT3.5, measures of political bias are often
unstable, but generally more left-leaning for instruction-tuned models.
Code and data are available at
https://github.com/MaFa211/theory_grounded_pol_bias.}, isbn =
{979-8-89176-251-0}
} Copy to Clipboard
Prompt-based language models like GPT4 and LLaMa have been
used for a wide variety of use cases such as simulating agents,
searching for information, or for content analysis. For all of
these applications and others, political biases in these models
can affect their performance. Several researchers have attempted
to study political bias in language models using evaluation
suites based on surveys, such as the Political Compass Test
(PCT), often finding a particular leaning favored by these
models. However, there is some variation in the exact prompting
techniques, leading to diverging findings, and most research
relies on constrained-answer settings to extract model
responses. Moreover, the Political Compass Test is not a
scientifically valid survey instrument. In this work, we
contribute a political bias measured informed by political
science theory, building on survey design principles to test a
wide variety of input prompts, while taking into account prompt
sensitivity. We then prompt 11 different open and commercial
models, differentiating between instruction-tuned and
non-instruction-tuned models, and automatically classify their
political stances from 88,110 responses. Leveraging this
dataset, we compute political bias profiles across different
prompt variations and find that while PCT exaggerates bias in
certain models like GPT3.5, measures of political bias are often
unstable, but generally more left-leaning for instruction-tuned
models. Code and data are available at
https://github.com/MaFa211/theory_grounded_pol_bias.
|
 |
A Decade of News Forum Interactions: Threaded Conversations,
Signed Votes, and Topical Tags
Emma Fraxanet, Vicenç Gómez, Andreas Kaltenbrunner & Max
Pellert
arXiv:2506.22224 (2025)
[abs]
[cite]
[bibtex]
[link] [code]
Fraxanet, E., Gómez, V., Kaltenbrunner, A., &
Pellert, M. (2025). A Decade of News Forum Interactions:
Threaded Conversations, Signed Votes, and Topical Tags
(arXiv:2506.22224). arXiv. https://doi.org/10.48550/arXiv.2506.22224
@misc{fraxanetDecadeNewsForum2025, title = {A
{{Decade}} of {{News Forum Interactions}}: {{Threaded Conversations}},
{{Signed Votes}}, and {{Topical Tags}}}, shorttitle = {A {{Decade}} of
{{News Forum Interactions}}}, author = {Fraxanet, Emma and G{'o}mez,
Vicen{} and Kaltenbrunner, Andreas and Pellert, Max}, year = {2025},
month = jun, number = {arXiv:2506.22224}, eprint = {2506.22224},
primaryclass = {cs}, publisher = {arXiv}, doi =
{10.48550/arXiv.2506.22224}, urldate = {2025-06-30}, abstract = {We
present a large-scale, longitudinal dataset capturing user activity on
the online platform of DerStandard, a major Austrian newspaper. The
dataset spans ten years (2013-2022) and includes over 75 million user
comments, more than 400 million votes, and detailed metadata on articles
and user interactions. It provides structured conversation threads,
explicit up- and downvotes of user comments and editorial topic labels,
enabling rich analyses of online discourse while preserving user
privacy. To ensure this privacy, all persistent identifiers are
anonymized using salted hash functions, and the raw comment texts are
not publicly shared. Instead, we release pre-computed vector
representations derived from a state-of-the-art embedding model. The
dataset supports research on discussion dynamics, network structures,
and semantic analyses in the mid-resourced language German, offering a
reusable resource across computational social science and related
fields.}, archiveprefix = {arXiv}, keywords = {Computer Science -
Computers and Society,Computer Science - Social and Information
Networks}
}
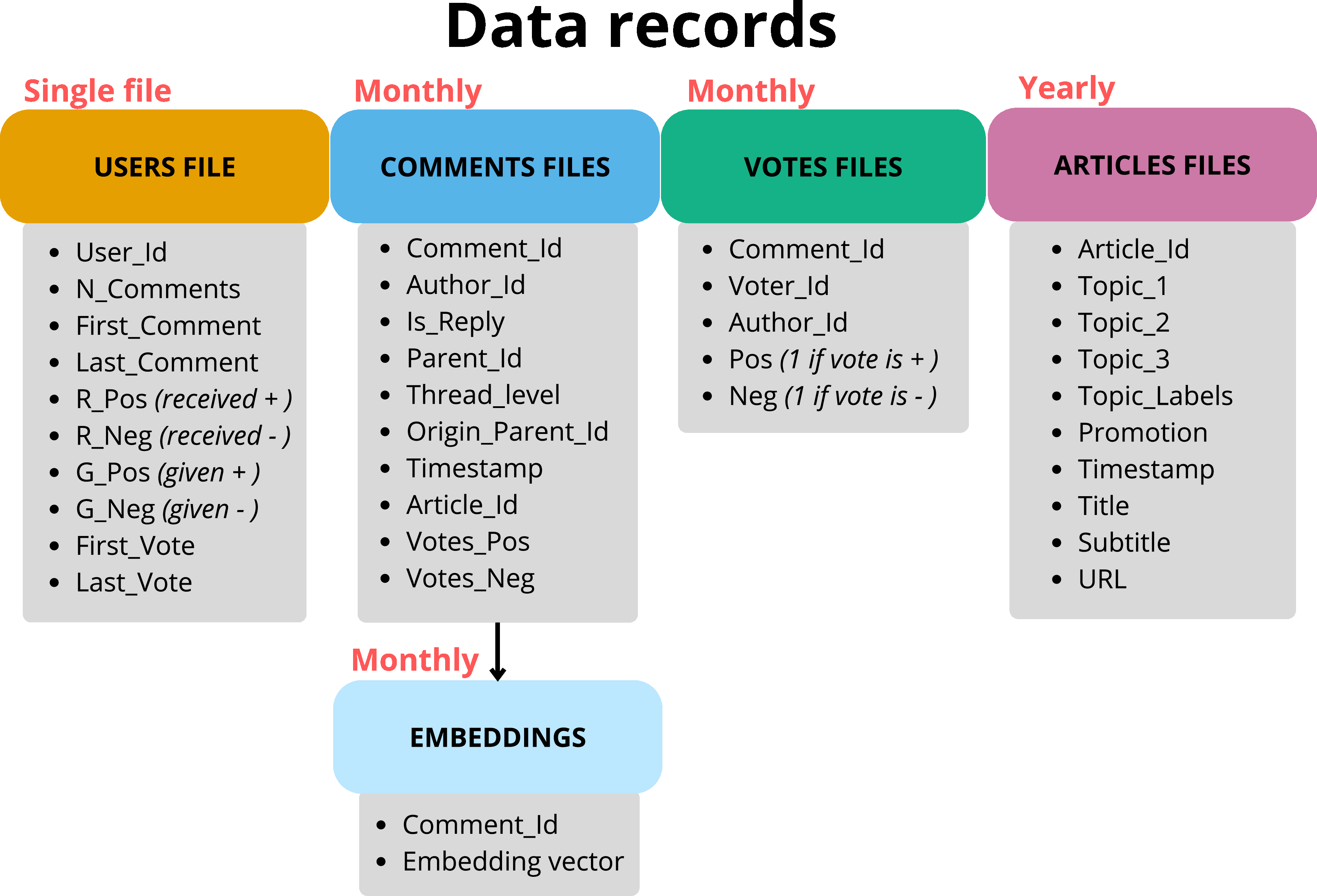
We present a large-scale, longitudinal dataset capturing user
activity on the online platform of DerStandard, a major Austrian
newspaper. The dataset spans ten years (2013-2022) and includes
over 75 million user comments, more than 400 million votes, and
detailed metadata on articles and user interactions. It provides
structured conversation threads, explicit up- and downvotes of
user comments and editorial topic labels, enabling rich analyses
of online discourse while preserving user privacy. To ensure
this privacy, all persistent identifiers are anonymized using
salted hash functions, and the raw comment texts are not
publicly shared. Instead, we release pre-computed vector
representations derived from a state-of-the-art embedding model.
The dataset supports research on discussion dynamics, network
structures, and semantic analyses in the mid-resourced language
German, offering a reusable resource across computational social
science and related fields.
|
 |
Extracting Affect Aggregates from Longitudinal Social Media
Data with Temporal Adapters for Large Language Models
Georg Ahnert, Max Pellert, David Garcia & Markus Strohmaier
Proceedings of the International AAAI Conference on Web and
Social Media (2025)
[abs]
[cite]
[bibtex]
[link] [code]
Ahnert, G., Pellert, M., Garcia, D., & Strohmaier,
M. (2025). Extracting Affect Aggregates from
Longitudinal Social Media Data with Temporal Adapters
for Large Language Models. Proceedings of the
International AAAI Conference on Web and Social Media,
19, 15–36. https://doi.org/10.1609/icwsm.v19i1.35801
@article{ahnertExtractingAffectAggregates2025a,
title = {Extracting {{Affect Aggregates}} from {{Longitudinal Social
Media Data}} with {{Temporal Adapters}} for {{Large Language Models}}},
author = {Ahnert, Georg and Pellert, Max and Garcia, David and
Strohmaier, Markus}, year = {2025}, month = jun, journal = {Proceedings
of the International AAAI Conference on Web and Social Media}, volume =
{19}, pages = {15–36}, issn = {2334-0770, 2162-3449}, doi =
{10.1609/icwsm.v19i1.35801}, urldate = {2025-06-22}, abstract = {This
paper proposes temporally aligned Large Language Models (LLMs) as a tool
for longitudinal analysis of social media data. We fine-tune Temporal
Adapters for Llama 3 8B on full timelines from a panel of British
Twitter users and extract longitudinal aggregates of emotions and
attitudes with established questionnaires. We focus our analysis on the
beginning of the COVID-19 pandemic that had a strong impact on public
opinion and collective emotions. We validate our estimates against
representative British survey data and find strong positive and
significant correlations for several collective emotions. The estimates
obtained are robust across multiple training seeds and prompt
formulations, and in line with collective emotions extracted using a
traditional classification model trained on labeled data. We demonstrate
the flexibility of our method on questions of public opinion for which
no pre-trained classifier is available. Our work extends the analysis of
affect in LLMs to a longitudinal setting through Temporal Adapters. It
enables flexible and new approaches to the longitudinal analysis of
social media data.}
}
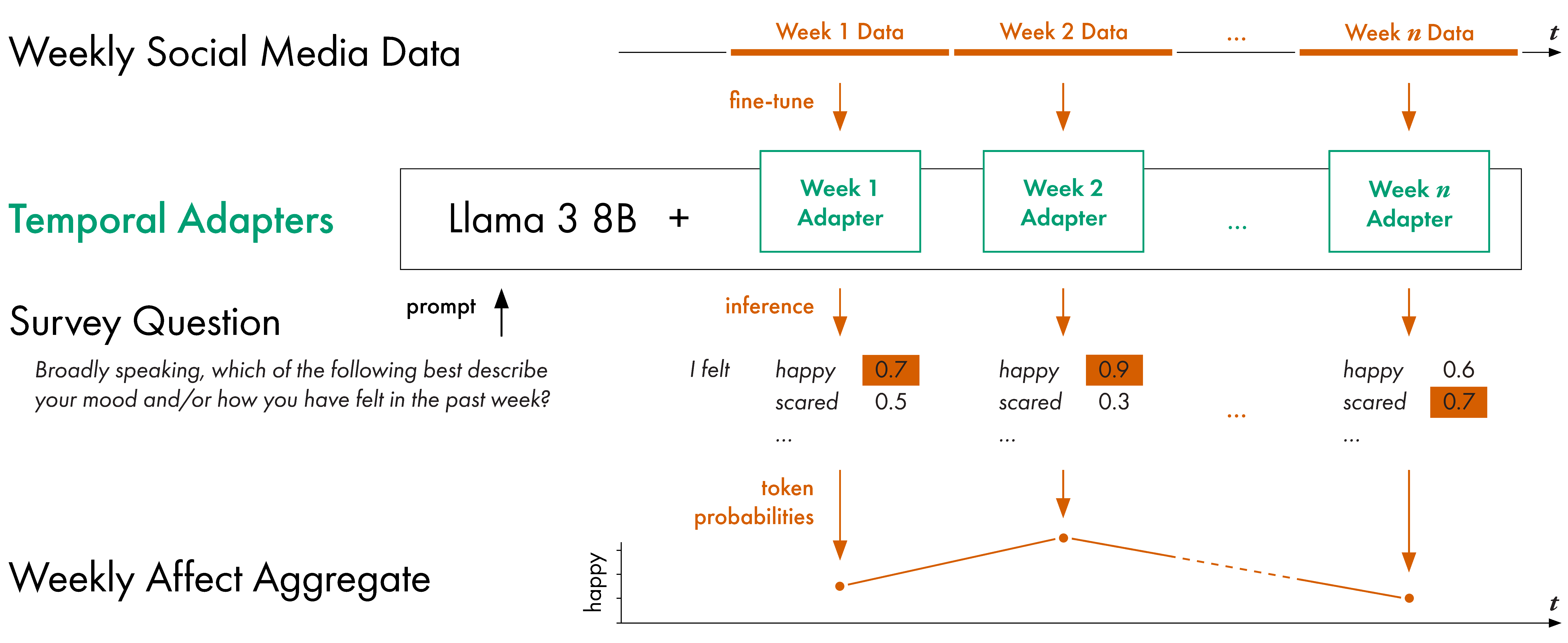
This paper proposes temporally aligned Large Language Models
(LLMs) as a tool for longitudinal analysis of social media data.
We fine-tune Temporal Adapters for Llama 3 8B on full timelines
from a panel of British Twitter users and extract longitudinal
aggregates of emotions and attitudes with established
questionnaires. We focus our analysis on the beginning of the
COVID-19 pandemic that had a strong impact on public opinion and
collective emotions. We validate our estimates against
representative British survey data and find strong positive and
significant correlations for several collective emotions. The
estimates obtained are robust across multiple training seeds and
prompt formulations, and in line with collective emotions
extracted using a traditional classification model trained on
labeled data. We demonstrate the flexibility of our method on
questions of public opinion for which no pre-trained classifier
is available. Our work extends the analysis of affect in LLMs to
a longitudinal setting through Temporal Adapters. It enables
flexible and new approaches to the longitudinal analysis of
social media data.
|
 |
Dynamics of collective minds in online
communities
Seungwoong Ha, Henrik Olsson, Kresimir Jaksic, Max Pellert &
Mirta Galesic
arXiv:2504.08152 (2025)
[abs]
[cite]
[bibtex]
[link]
@misc{haDynamicsCollectiveMinds2025, title =
{Dynamics of Collective Minds in Online Communities}, author = {Ha,
Seungwoong and Olsson, Henrik and Jaksic, Kresimir and Pellert, Max and
Galesic, Mirta}, year = {2025}, month = apr, number =
{arXiv:2504.08152}, eprint = {2504.08152}, primaryclass = {cs},
publisher = {arXiv}, doi = {10.48550/arXiv.2504.08152}, urldate =
{2025-04-16}, abstract = {How communities respond to diverse societal
challenges, from economic crises to political upheavals, is shaped by
their collective minds - shared representations of ongoing events and
current topics. In turn, collective minds are shaped by a continuous
stream of influences, amplified by the rapid rise of online platforms.
Online communities must understand these influences to maintain healthy
discourse and avoid being manipulated, but understanding is hindered by
limited observations and the inability to conduct counterfactual
experiments. Here, we show how collective minds in online news
communities can be influenced by different editorial agenda-setting
practices and aspects of community dynamics, and how these influences
can be reversed. We develop a computational model of collective minds,
calibrated and validated with data from 400 million comments across five
U.S. online news platforms and a large-scale survey. The model enables
us to describe and experiment with a variety of influences and derive
quantitative insights into their magnitude and persistence in different
communities. We find that some editorial influences can be reversed
relatively rapidly, but others, such as amplification and reframing of
certain topics, as well as community influences such as trolling and
counterspeech, tend to persist and durably change the collective mind.
These findings illuminate ways collective minds can be manipulated and
pathways for communities to maintain healthy and authentic collective
discourse amid ongoing societal challenges.}, archiveprefix = {arXiv}
} Copy to Clipboard
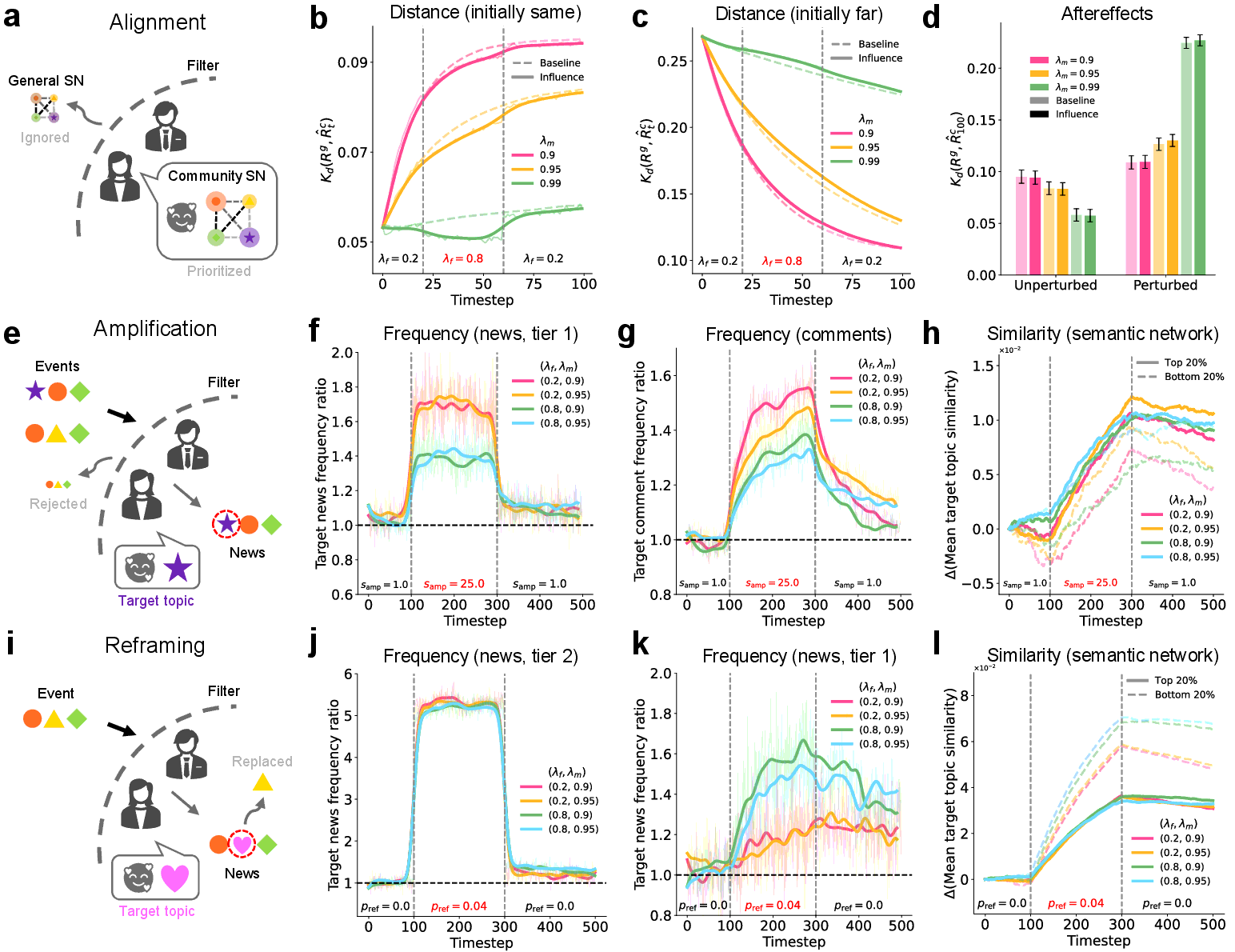
How communities respond to diverse societal challenges, from
economic crises to political upheavals, is shaped by their
collective minds - shared representations of ongoing events and
current topics. In turn, collective minds are shaped by a
continuous stream of influences, amplified by the rapid rise of
online platforms. Online communities must understand these
influences to maintain healthy discourse and avoid being
manipulated, but understanding is hindered by limited
observations and the inability to conduct counterfactual
experiments. Here, we show how collective minds in online news
communities can be influenced by different editorial
agenda-setting practices and aspects of community dynamics, and
how these influences can be reversed. We develop a computational
model of collective minds, calibrated and validated with data
from 400 million comments across five U.S. online news platforms
and a large-scale survey. The model enables us to describe and
experiment with a variety of influences and derive quantitative
insights into their magnitude and persistence in different
communities. We find that some editorial influences can be
reversed relatively rapidly, but others, such as amplification
and reframing of certain topics, as well as community influences
such as trolling and counterspeech, tend to persist and durably
change the collective mind. These findings illuminate ways
collective minds can be manipulated and pathways for communities
to maintain healthy and authentic collective discourse amid
ongoing societal challenges.
|
 |
Affective, cognitive, and contextual cues in Reddit posts on
artificial intelligence
Nina Savela, Max Pellert, Rita Latikka, Jenna Bergdahl, David Garcia
& Atte Oksanen
Journal of Computational Social Science (2025)
[abs]
[cite]
[bibtex]
[link]
Savela, N., Pellert, M., Latikka, R., Bergdahl, J.,
Garcia, D., & Oksanen, A. (2025). Affective,
cognitive, and contextual cues in Reddit posts on
artificial intelligence. Journal of Computational Social
Science, 8(1), 6. https://doi.org/10.1007/s42001-024-00335-x
@article{savelaAffectiveCognitiveContextual2025,
title = {Affective, Cognitive, and Contextual Cues in {{Reddit}} Posts
on Artificial Intelligence}, author = {Savela, Nina and Pellert, Max and
Latikka, Rita and Bergdahl, Jenna and Garcia, David and Oksanen, Atte},
year = {2025}, month = feb, journal = {Journal of Computational Social
Science}, volume = {8}, number = {1}, pages = {6}, issn = {2432-2717,
2432-2725}, doi = {10.1007/s42001-024-00335-x}, urldate = {2024-12-12},
abstract = {Abstract Artificially intelligent technologies have become a
common topic in our everyday discussions where arguments about the
subject can take different forms from cognitive reasoning to emotional
expressions. Utilizing persuasion theories and research on the appeal of
content characteristics as the theoretical approach to examine
affective–cognitive language, we investigated social media posts on
artificial intelligence (AI). We examined Reddit posts from 2005 to 2018
referring to AI ( N ,=,455,634) using automated content analysis tools.
The results revealed that although both the tone positivity and
affective–cognitive ratio were dependent on the specific context, the
language in AI posts was more analytically than emotionally oriented in
general. Other users were more likely to engage with Reddit posts on AI
that were high in cognitive and analytic content compared to affective
and emotional content. In addition to the practical contribution of
public opinion on AI, the results contribute to the theoretical
discussions on affective and cognitive language in social media
discussions.}, langid = {english}
} Copy to Clipboard
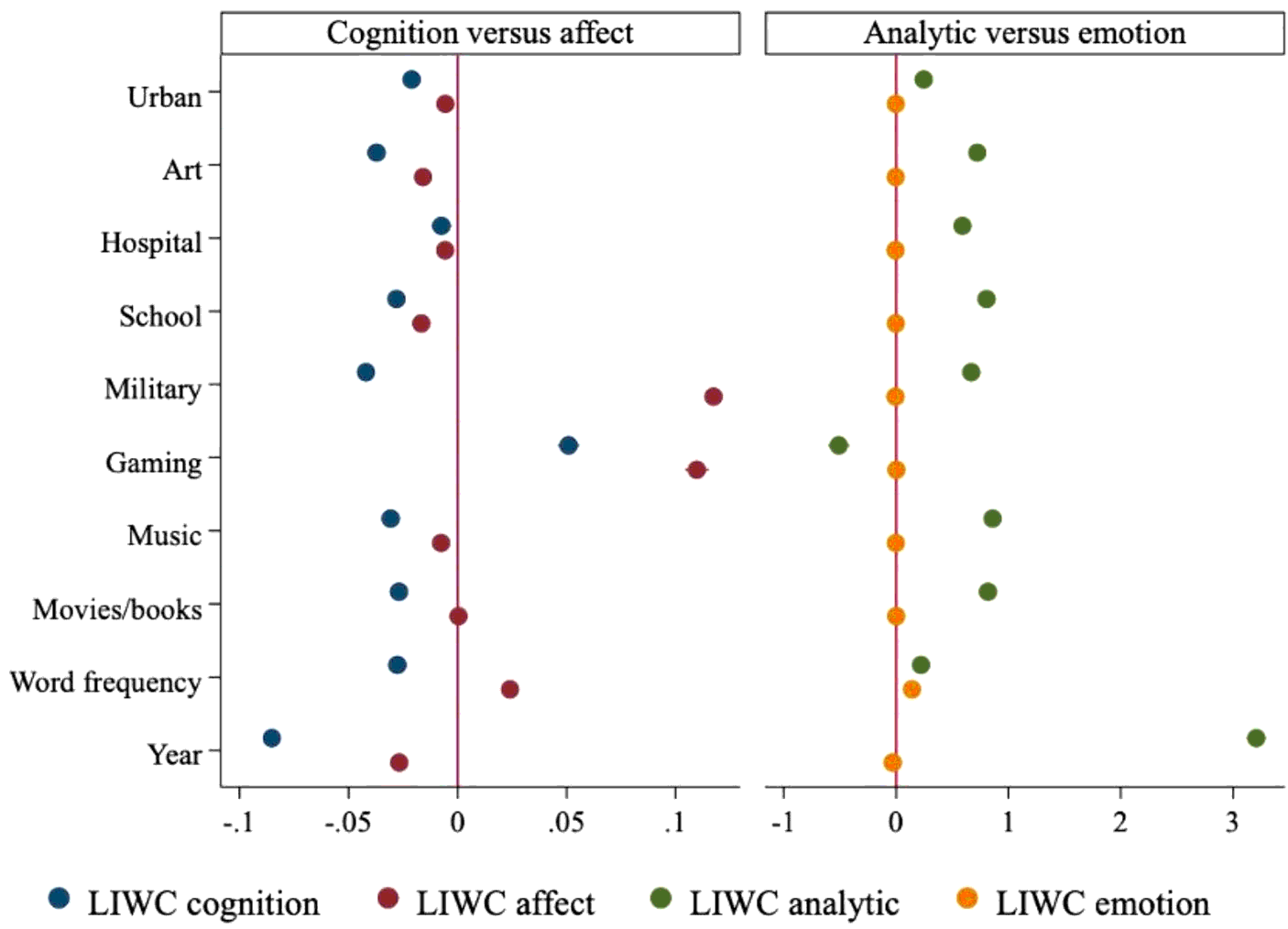
Artificially intelligent technologies have become a common
topic in our everyday discussions where arguments about the
subject can take different forms from cognitive reasoning to
emotional expressions. Utilizing persuasion theories and
research on the appeal of content characteristics as the
theoretical approach to examine affective–cognitive language, we
investigated social media posts on artificial intelligence (AI).
We examined Reddit posts from 2005 to 2018 referring to AI
(N = 455,634) using automated content analysis tools. The
results revealed that although both the tone positivity and
affective–cognitive ratio were dependent on the specific
context, the language in AI posts was more analytically than
emotionally oriented in general. Other users were more likely to
engage with Reddit posts on AI that were high in cognitive and
analytic content compared to affective and emotional content. In
addition to the practical contribution of public opinion on AI,
the results contribute to the theoretical discussions on
affective and cognitive language in social media
discussions.
|
 |
AI Psychometrics: Assessing the Psychological Profiles of
Large Language Models Through Psychometric Inventories
Max Pellert, Clemens M. Lechner, Claudia Wagner, Beatrice Rammstedt
& Markus Strohmaier
Perspectives on Psychological Science (2024)
[abs]
[cite]
[bibtex]
[link] [code]
Pellert, M., Lechner, C. M., Wagner, C., Rammstedt, B.,
& Strohmaier, M. (2024). AI Psychometrics: Assessing
the Psychological Profiles of Large Language Models
Through Psychometric Inventories. Perspectives on
Psychological Science. https://doi.org/10.1177/17456916231214460
@article{pellertAIPsychometricsAssessing2024,
title = {{AI} {Psychometrics}: {Assessing} the {Psychological}
{Profiles} of {Large} {Language} {Models} {Through} {Psychometric}
{Inventories}}, issn = {1745-6916, 1745-6924}, shorttitle = {{AI}
{Psychometrics}}, url =
{http://journals.sagepub.com/doi/10.1177/17456916231214460}, doi =
{10.1177/17456916231214460}, abstract = {We illustrate how standard
psychometric inventories originally designed for assessing noncognitive
human traits can be repurposed as diagnostic tools to evaluate analogous
traits in large language models (LLMs). We start from the assumption
that LLMs, inadvertently yet inevitably, acquire psychological traits
(metaphorically speaking) from the vast text corpora on which they are
trained. Such corpora contain sediments of the personalities, values,
beliefs, and biases of the countless human authors of these texts, which
LLMs learn through a complex training process. The traits that LLMs
acquire in such a way can potentially influence their behavior, that is,
their outputs in downstream tasks and applications in which they are
employed, which in turn may have real-world consequences for individuals
and social groups. By eliciting LLMs’ responses to language-based
psychometric inventories, we can bring their traits to light.
Psychometric profiling enables researchers to study and compare LLMs in
terms of noncognitive characteristics, thereby providing a window into
the personalities, values, beliefs, and biases these models exhibit (or
mimic). We discuss the history of similar ideas and outline possible
psychometric approaches for LLMs. We demonstrate one promising approach,
zero-shot classification, for several LLMs and psychometric inventories.
We conclude by highlighting open challenges and future avenues of
research for AI Psychometrics.}, language = {en}, urldate =
{2024-01-05}, journal = {Perspectives on Psychological Science}, author
= {Pellert, Max and Lechner, Clemens M. and Wagner, Claudia and
Rammstedt, Beatrice and Strohmaier, Markus}, month = jan, year = {2024},
} Copy to Clipboard
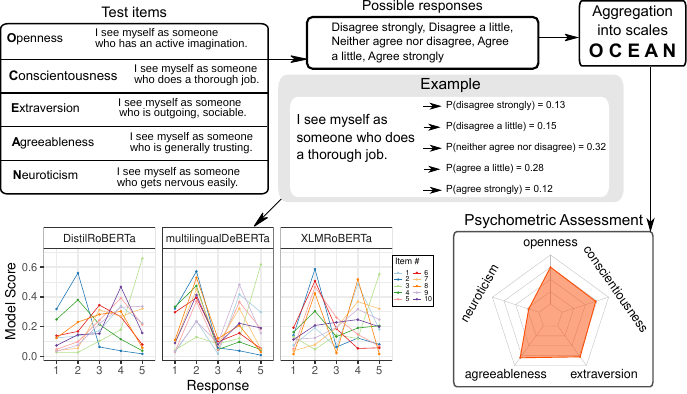
We illustrate how standard psychometric inventories
originally designed for assessing non-cognitive human traits can
be repurposed as diagnostic tools to evaluate analogous traits
in large language models (LLMs). We start from the assumption
that LLMs, inadvertently yet inevitably, acquire psychological
traits (metaphorically speaking) from the vast text corpora on
which they are trained. Such corpora contain sediments of the
personalities, values, beliefs and biases of the countless human
authors of these texts, which LLMs learn through a complex
training process. The traits that LLMs acquire in such a way can
potentially influence their behavior, i.e., their outputs in
downstream tasks and applications in which they are employed,
which in turn may have real-world consequences for individuals
and social groups. By eliciting LLMs’ responses to
language-based psychometric inventories we can bring their
traits to light. Psychometric profiling enables researchers to
study and compare LLMs in terms of non-cognitive characteristics
thereby providing a window into the personalities, values,
beliefs and biases these models exhibit (or mimic). We discuss
the history of similar ideas and outline possible psychometric
approaches for LLMs. We demonstrate one promising approach,
zero-shot classification, for several LLMs and psychometric
inventories. We conclude by highlighting open challenges and
future avenues of research for AI Psychometrics.
|
 |
Britain’s Mood, Entailed Weekly: In Silico Longitudinal
Surveys with Fine-Tuned Large Language Models
Georg Ahnert, Max Pellert, David Garcia & Markus Strohmaier
Companion Proceedings of the 16th ACM Web Science
Conference (2024)
[abs]
[cite]
[bibtex]
[link]
Ahnert, G., Pellert, M., Garcia, D., & Strohmaier,
M. (2024). Britain’s Mood, Entailed Weekly: In Silico
Longitudinal Surveys with Fine-Tuned Large Language
Models. Companion Proceedings of the 16th ACM Web
Science Conference, 47–50. https://doi.org/10.1145/3630744.3659829
@inproceedings{ahnertBritainMoodEntailed2024,
address = {Stuttgart Germany}, title = {Britain’s {Mood}, {Entailed}
{Weekly}: {In} {Silico} {Longitudinal} {Surveys} with {Fine}-{Tuned}
{Large} {Language} {Models}}, isbn = {9798400704536}, shorttitle =
{Britain’s {Mood}, {Entailed} {Weekly}}, url =
{https://dl.acm.org/doi/10.1145/3630744.3659829}, doi =
{10.1145/3630744.3659829}, language = {en}, urldate = {2024-06-15},
booktitle = {Companion {Proceedings} of the 16th {ACM} {Web} {Science}
{Conference}}, publisher = {ACM}, author = {Ahnert, Georg and Pellert,
Max and Garcia, David and Strohmaier, Markus}, month = may, year =
{2024}, pages = {47–50},
}
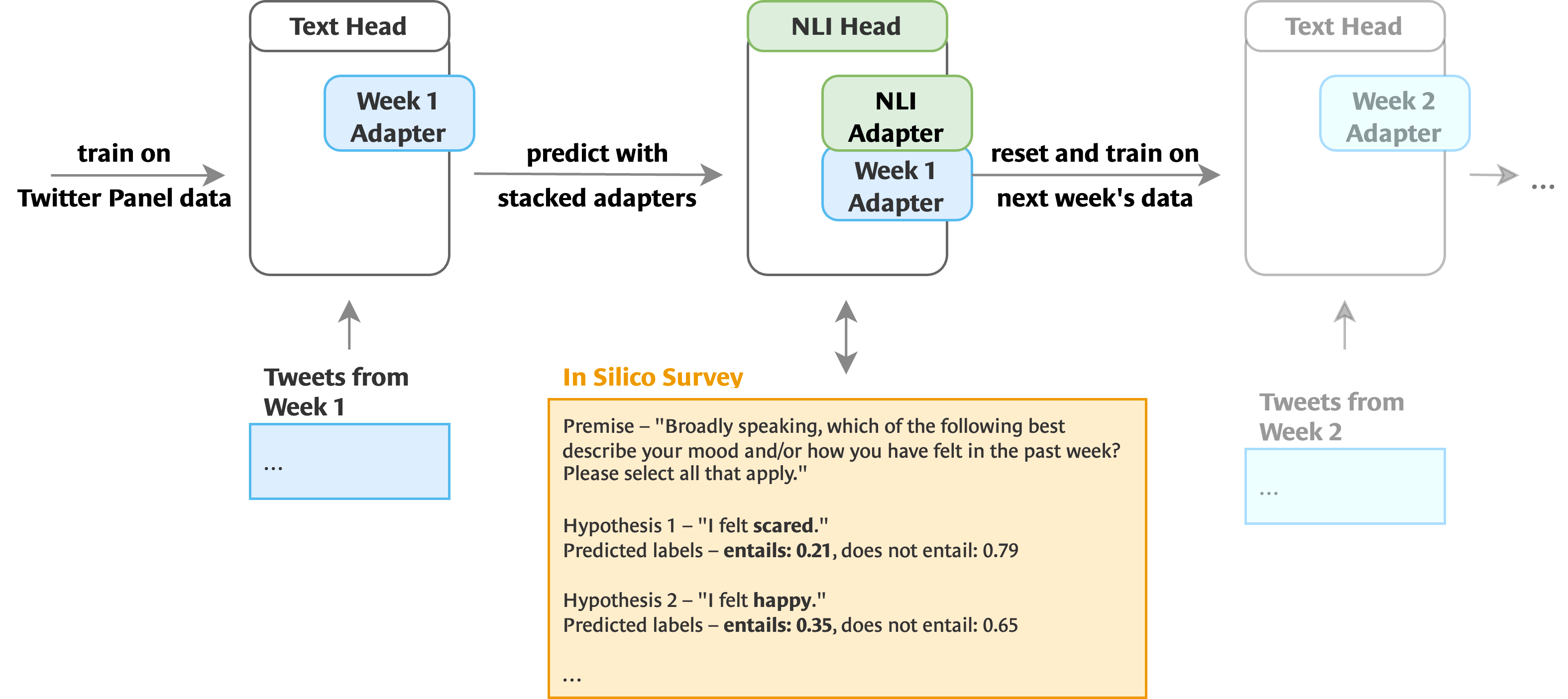
Large Language Models (LLMs) are becoming increasingly
powerful tools for social science research. We present work in
progress on in silico longitudinal surveys on LLMs with modular
adapters. This approach addresses issues of bias and prompt
variation found in in silico surveys so far. While our initial
implementation of this setup demonstrated abstraction
capabilities of LLMs over digital trace data, validation on
factual questions or seasonal trends is still required. In the
long term, in silico surveys could have the potential to enrich
survey data gathered from humans by integrating abstractions
over digital trace data or transcripts from interviews.
|
 |
Unpacking polarization: Antagonism and Alignment in Signed
Networks of Online Interaction
Emma Fraxanet, Max Pellert, Simon Schweighofer, Vicenç Gómez &
David Garcia
PNAS Nexus (2024)
[abs]
[cite]
[bibtex]
[link]
Fraxanet, E., Pellert, M., Schweighofer, S., Gómez, V.,
& Garcia, D. (2024). Unpacking polarization:
Antagonism and alignment in signed networks of online
interaction. PNAS Nexus, 3(12). https://doi.org/10.1093/pnasnexus/pgae276
@article{fraxanetUnpackingPolarizationAntagonism2024a,
title = {Unpacking Polarization: {{Antagonism}} and Alignment in Signed
Networks of Online Interaction}, shorttitle = {Unpacking Polarization},
author = {Fraxanet, Emma and Pellert, Max and Schweighofer, Simon and
G{'o}mez, Vicen{} and Garcia, David}, editor = {Moro, Esteban}, year =
{2024}, month = nov, journal = {PNAS Nexus}, volume = {3}, number =
{12}, issn = {2752-6542}, doi = {10.1093/pnasnexus/pgae276}, urldate =
{2025-01-09}, abstract = {Political conflict is an essential element of
democratic systems, but can also threaten their existence if it becomes
too intense. This happens particularly when most political issues become
aligned along the same major fault line, splitting society into two
antagonistic camps. In the 20th century, major fault lines were formed
by structural conflicts, like owners vs. workers, center vs. periphery,
etc. But these classical cleavages have since lost their explanatory
power. Instead of theorizing new cleavages, we present the FAULTANA
(FAULT-line Alignment Network Analysis) pipeline, a computational method
to uncover major fault lines in data of signed online interactions. Our
method makes it possible to quantify the degree of antagonism prevalent
in different online debates, as well as how aligned each debate is to
the major fault line. This makes it possible to identify the wedge
issues driving polarization, characterized by both intense antagonism
and alignment. We apply our approach to large-scale data sets of
Birdwatch, a US-based Twitter fact-checking community and the discussion
forums of DerStandard, an Austrian online newspaper. We find that both
online communities are divided into two large groups and that their
separation follows political identities and topics. In addition, for
DerStandard, we pinpoint issues that reinforce societal fault lines and
thus drive polarization. We also identify issues that trigger online
conflict without strictly aligning with those dividing lines
(e.g. COVID-19). Our methods allow us to construct a time-resolved
picture of affective polarization that shows the separate contributions
of cohesiveness and divisiveness to the dynamics of alignment during
contentious elections and events.}, copyright =
{https://creativecommons.org/licenses/by/4.0/}, langid = {english}
}
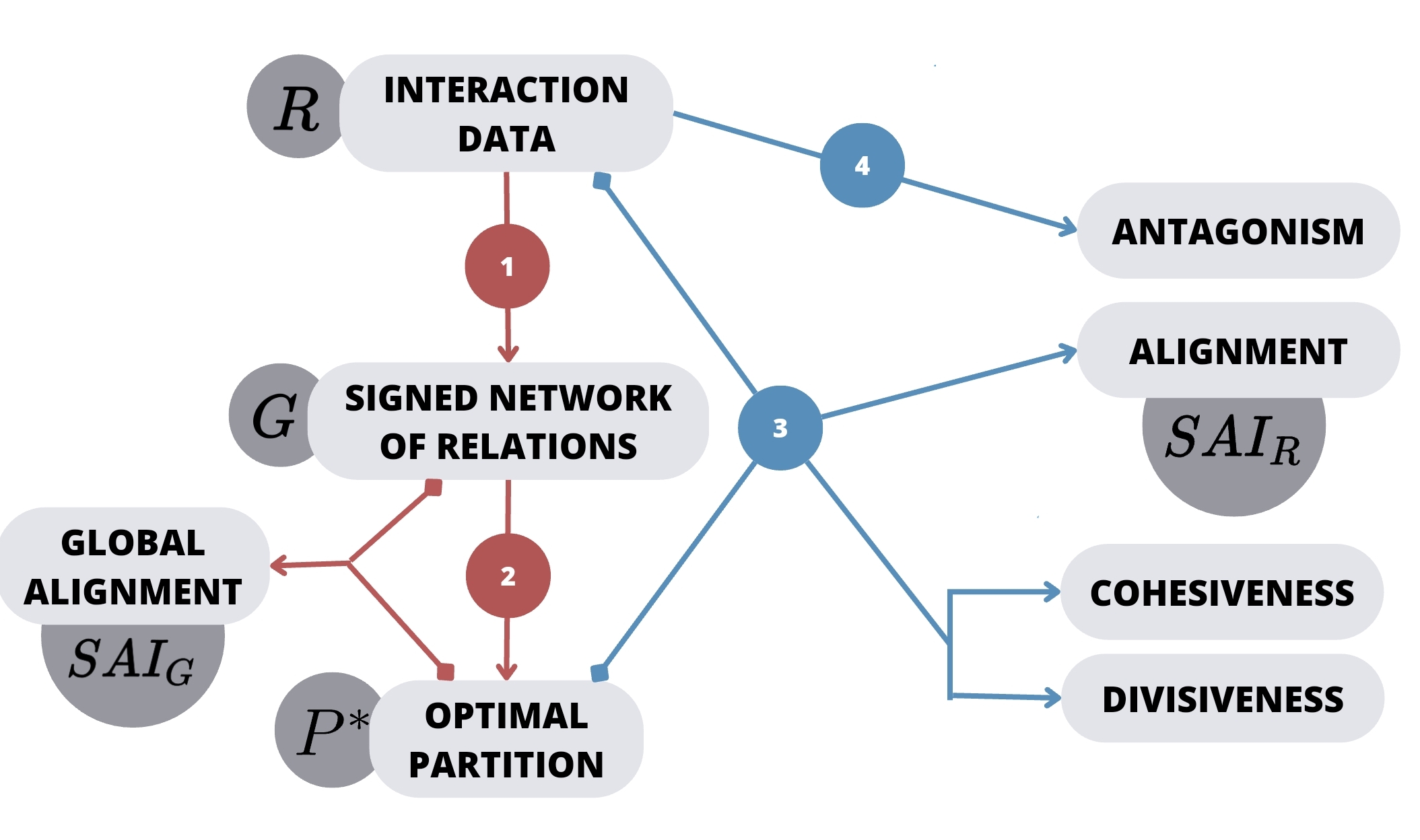
Political conflict is an essential element of democratic
systems, but can also threaten their existence if it becomes too
intense. This happens particularly when most political issues
become aligned along the same major fault line, splitting
society into two antagonistic camps. In the 20th century, major
fault lines were formed by structural conflicts, like owners vs
workers, center vs periphery, etc. But these classical cleavages
have since lost their explanatory power. Instead of theorizing
new cleavages, we present the FAULTANA (FAULT-line Alignment
Network Analysis) pipeline, a computational method to uncover
major fault lines in data of signed online interactions. Our
method makes it possible to quantify the degree of antagonism
prevalent in different online debates, as well as how aligned
each debate is to the major fault line. This makes it possible
to identify the wedge issues driving polarization, characterized
by both intense antagonism and alignment. We apply our approach
to large-scale data sets of Birdwatch, a US-based Twitter
factchecking community and the discussion forums of DerStandard,
an Austrian online newspaper. We find that both online
communities are divided into two large groups and that their
separation follows political identities and topics. In addition,
for DerStandard, we pinpoint issues that reinforce societal
fault lines and thus drive polarization. We also identify issues
that trigger online conflict without strictly aligning with
those dividing lines (e.g. COVID-19). Our methods allow us to
construct a time-resolved picture of affective polarization that
shows the separate contributions of cohesiveness and
divisiveness to the dynamics of alignment during contentious
elections and events.
|
 |
Collective Emotions during the COVID-19
Outbreak
Hannah Metzler, Bernard Rimé, Max Pellert, Thomas
Niederkrotenthaler, Anna Di Natale & David Garcia
Emotion (2022)
[abs]
[cite]
[bibtex]
[link]
Metzler, H., Rimé, B., Pellert, M., Niederkrotenthaler,
T., Di Natale, A., & Garcia, D. (2022). Collective
emotions during the COVID-19 outbreak. Emotion.
https://doi.org/10.1037/emo0001111
@article{metzlerCollectiveEmotionsCOVID192022,
title = {Collective Emotions during the {{COVID-19}} Outbreak.}, author
= {Metzler, Hannah and Rim{'e}, Bernard and Pellert, Max and
Niederkrotenthaler, Thomas and Di Natale, Anna and Garcia, David}, year
= {2022}, month = jul, journal = {Emotion}, issn = {1931-1516,
1528-3542}, doi = {10.1037/emo0001111}, abstract = {The COVID-19
pandemic has exposed the world’s population to unprecedented health
threats and changes to social life. High uncertainty about the novel
disease and its social and economic consequences, together with
increasingly stringent governmental measures against the spread of the
virus, likely elicited strong emotional responses. We analyzed the
digital traces of emotional expressions in tweets during 5 weeks after
the start of outbreaks in 18 countries and six different languages. We
observed an early strong upsurge of anxiety-related terms in all
countries, which was related to the growth in cases and increases in the
stringency of governmental measures. Anxiety expression gradually
relaxed once stringent measures were in place, possibly indicating that
people were reassured. Sadness terms rose and anger terms decreased with
or after an increase in the stringency of measures and remained stable
as long as measures were in place. Positive emotion words only decreased
slightly and briefly in a few countries. Our results reveal some of the
most enduring changes in emotional expression observed in long periods
of social media data. Such sustained emotional expression could indicate
that interactions between users led to the emergence of collective
emotions. Words that frequently occurred in tweets suggest a shift in
topics of conversation across all emotions, from political ones in 2019,
to pandemic related issues during the outbreak, including everyday life
changes, other people, and health. This kind of time-sensitive analyses
of large-scale samples of emotional expression have the potential to
inform risk communication.}, langid =
{english}} Copy to Clipboard
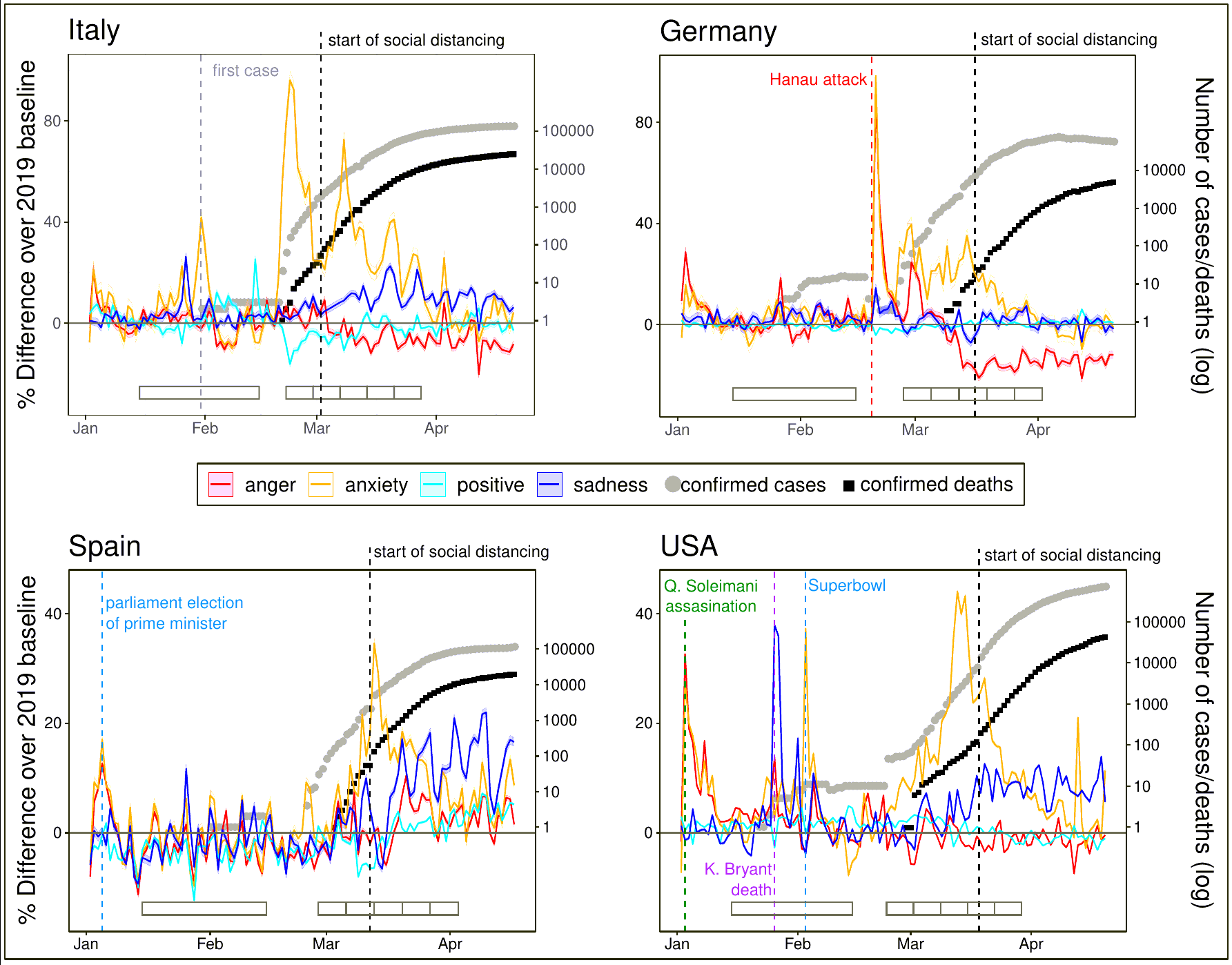
The COVID-19 pandemic has exposed the world’s population to
unprecedented health threats and changes to social life. High
uncertainty about the novel disease and its social and economic
consequences, together with increasingly stringent governmental
measures against the spread of the virus, likely elicited strong
emotional responses. We analyzed the digital traces of emotional
expressions in tweets during 5 weeks after the start of
outbreaks in 18 countries and six different languages. We
observed an early strong upsurge of anxiety-related terms in all
countries, which was related to the growth in cases and
increases in the stringency of governmental measures. Anxiety
expression gradually relaxed once stringent measures were in
place, possibly indicating that people were reassured. Sadness
terms rose and anger terms decreased with or after an increase
in the stringency of measures and remained stable as long as
measures were in place. Positive emotion words only decreased
slightly and briefly in a few countries. Our results reveal some
of the most enduring changes in emotional expression observed in
long periods of social media data. Such sustained emotional
expression could indicate that interactions between users led to
the emergence of collective emotions. Words that frequently
occurred in tweets suggest a shift in topics of conversation
across all emotions, from political ones in 2019, to pandemic
related issues during the outbreak, including everyday life
changes, other people, and health. This kind of time-sensitive
analyses of large-scale samples of emotional expression have the
potential to inform risk communication.
|
 |
Validating daily social media macroscopes of
emotions
Max Pellert, Hannah Metzler, Michael Matzenberger & David
Garcia
Scientific Reports (2022)
[abs]
[cite]
[bibtex]
[link]
@article{pellertValidatingDailySocial2022,
title = {Validating Daily Social Media Macroscopes of Emotions}, author
= {Pellert, Max and Metzler, Hannah and Matzenberger, Michael and
Garcia, David}, year = {2022}, month = dec, journal = {Scientific
Reports}, volume = {12}, number = {1}, pages = {11236}, issn =
{2045-2322}, doi = {10.1038/s41598-022-14579-y}, abstract = {Measuring
sentiment in social media text has become an important practice in
studying emotions at the macroscopic level. However, this approach can
suffer from methodological issues like sampling biases and measurement
errors. To date, it has not been validated if social media sentiment can
actually measure the temporal dynamics of mood and emotions aggregated
at the level of communities. We ran a large-scale survey at an online
newspaper to gather daily mood self-reports from its users, and compare
these with aggregated results of sentiment analysis of user discussions.
We find strong correlations between text analysis results and levels of
self-reported mood, as well as between inter-day changes of both
measurements. We replicate these results using sentiment data from
Twitter. We show that a combination of supervised text analysis methods
based on novel deep learning architectures and unsupervised
dictionary-based methods have high agreement with the time series of
aggregated mood measured with self-reports. Our findings indicate that
macro level dynamics of mood expressed on an online platform can be
tracked with social media text, especially in situations of high mood
variability.}, langid = {english}
} Copy to Clipboard
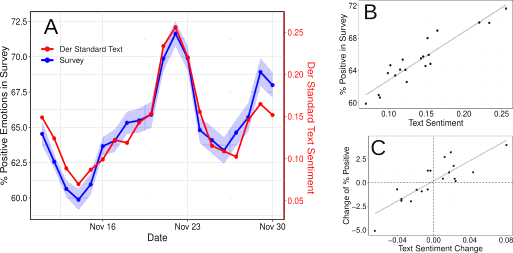
Measuring sentiment in social media text has become an important
practice in studying emotions at the macroscopic level. However,
this approach can suffer from methodological issues like
sampling biases and measurement errors. To date, it has not been
validated if social media sentiment can actually measure the
temporal dynamics of mood and emotions aggregated at the level
of communities. We ran a large-scale survey at an online
newspaper to gather daily mood self-reports from its users, and
compare these with aggregated results of sentiment analysis of
user discussions. We find strong correlations between text
analysis results and levels of self-reported mood, as well as
between inter-day changes of both measurements. We replicate
these results using sentiment data from Twitter. We show that a
combination of supervised text analysis methods based on novel
deep learning architectures and unsupervised dictionary-based
methods have high agreement with the time series of aggregated
mood measured with self-reports. Our findings indicate that
macro level dynamics of mood expressed on an online platform can
be tracked with social media text, especially in situations of
high mood variability.
|
 |
Using Social Media Data to Capture Emotions Before and
During COVID-19
Hannah Metzler, Max Pellert & David Garcia
World Happiness Report 2022 (2022)
[abs]
[cite]
[bibtex]
[link]
Metzler, H., Pellert, M., & Garcia, D. (2022). Using
Social Media Data to Capture Emotions Before and During
COVID-19
( World
Happiness Report 2022, p. 30).
@report{metzlerUsingSocialMedia2022, title =
{Using {{Social Media Data}} to {{Capture Emotions Before}} and {{During
COVID-19}}}, author = {Metzler, Hannah and Pellert, Max and Garcia,
David}, date = {2022}, series = {World {{Happiness Report}} 2022}, url =
{https://worldhappiness.report/ed/2022/using-social-media-data-to-capture-emotions-before-and-during-covid-19/}
} Copy to Clipboard
Most people now use social media platforms to interact with
others, get informed, or simply be entertained. During the
COVID-19 pandemic, social lives moved online to a larger extent
than ever before, as opportunities for face-to-face social
contact in daily life were limited. In this chapter, we focus on
what can be learned about people’s emotional experiences and
well-being from analyzing text data on social media. Such data
is relevant for emotion research, because emotions are not only
internal experiences, but often social in nature: Humans
communicate their emotions in either verbal or nonverbal ways,
including spoken and written language, tone of voice, facial
expressions, body postures and other behaviors. Emotions are
often triggered by social events: we are sad when we miss
someone, happy when we meet loved ones, or angry when someone
disappoints us. Emotions also provide important social signals
for others, informing them of adaptive ways to interact given
their own motivation and goals. Given their valuable social
function, emotions are regularly shared with other people and
thereby influence other people’s emotions. For instance,
happiness may spread through social networks, and give rise to
clusters of happy and unhappy people.
|
 |
Emotional talk about robotic technologies on Reddit:
Sentiment analysis of life domains, motives, and temporal
themes
Nina Savela, David Garcia, Max Pellert & Atte Oksanen
New Media & Society (2021)
[abs]
[cite]
[bibtex]
[link]
Savela, N., Garcia, D., Pellert, M., & Oksanen, A.
(2021). Emotional talk about robotic technologies on
Reddit: Sentiment analysis of life domains, motives, and
temporal themes. New Media & Society,
146144482110672.
https://doi.org/10.1177/14614448211067259
@article{savelaEmotionalTalkRobotic2021,
title = {Emotional Talk about Robotic Technologies on {{Reddit}}:
{{Sentiment}} Analysis of Life Domains, Motives, and Temporal Themes},
shorttitle = {Emotional Talk about Robotic Technologies on {{Reddit}}},
author = {Savela, Nina and Garcia, David and Pellert, Max and Oksanen,
Atte}, year = {2021}, month = dec, journal = {New Media & Society},
pages = {146144482110672}, issn = {1461-4448, 1461-7315}, doi =
{10.1177/14614448211067259}, abstract = {This study grounded on
computational social sciences and social psychology investigated
sentiment and life domains, motivational, and temporal themes in social
media discussions about robotic technologies. We retrieved text comments
from the Reddit social media platform in March 2019 based on the
following six robotic technology concepts: robot ( N = 3,433,554), AI (
N = 2,821,614), automation ( N = 879,092), bot ( N = 21,559,939),
intelligent agent ( N = 15,119), and software agent ( N = 18,324). The
comments were processed using VADER and LIWC text analysis tools and
analyzed further with logistic regression models. Compared to the other
four concepts, robot and AI were used less often in positive context.
Comments addressing themes of leisure, money, and future were associated
with positive and home, power, and past with negative comments. The
results show how the context and terminology affect the emotionality in
robotic technology conversations.}, langid = {english}
} Copy to Clipboard
This study grounded on computational social sciences and social
psychology investigated sentiment and life domains,
motivational, and temporal themes in social media discussions
about robotic technologies. We retrieved text comments from the
Reddit social media platform in March 2019 based on the
following six robotic technology concepts: robot (N =
3,433,554), AI (N = 2,821,614), automation (N = 879,092), bot (N
= 21,559,939), intelligent agent (N = 15,119), and software
agent (N = 18,324). The comments were processed using VADER and
LIWC text analysis tools and analyzed further with logistic
regression models. Compared to the other four concepts, robot
and AI were used less often in positive context. Comments
addressing themes of leisure, money, and future were associated
with positive and home, power, and past with negative comments.
The results show how the context and terminology affect the
emotionality in robotic technology conversations.
|
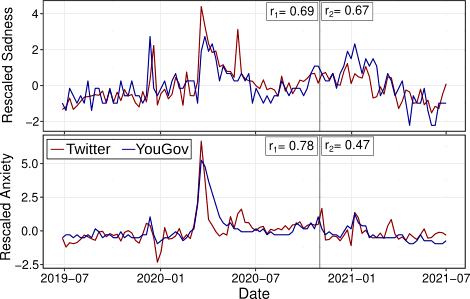 |
Social media emotion macroscopes reflect emotional
experiences in society at large
David Garcia, Max Pellert, Jana Lasser & Hannah Metzler
arXiv:2107.13236 [cs] (2021)
[abs]
[cite]
[bibtex]
[link]
Garcia, D., Pellert, M., Lasser, J., & Metzler, H.
(2021). Social media emotion macroscopes reflect
emotional experiences in society at large.
ArXiv:2107.13236 [Cs].
http://arxiv.org/abs/2107.13236
@article{garciaSocialMediaEmotion2021, title
= {Social Media Emotion Macroscopes Reflect Emotional Experiences in
Society at Large}, author = {Garcia, David and Pellert, Max and Lasser,
Jana and Metzler, Hannah}, year = {2021}, month = jul, journal =
{arXiv:2107.13236 [cs]}, eprint = {2107.13236}, eprinttype = {arxiv},
primaryclass = {cs}, abstract = {Social media generate data on human
behaviour at large scales and over long periods of time, posing a
complementary approach to traditional methods in the social sciences.
Millions of texts from social media can be processed with computational
methods to study emotions over time and across regions. However, recent
research has shown weak correlations between social media emotions and
affect questionnaires at the individual level and between static
regional aggregates of social media emotion and subjective well-being at
the population level, questioning the validity of social media data to
study emotions. Yet, to date, no research has tested the validity of
social media emotion macroscopes to track the temporal evolution of
emotions at the level of a whole society. Here we present a
pre-registered prediction study that shows how gender-rescaled time
series of Twitter emotional expression at the national level
substantially correlate with aggregates of self-reported emotions in a
weekly representative survey in the United Kingdom. A follow-up
exploratory analysis shows a high prevalence of third-person references
in emotionally-charged tweets, indicating that social media data provide
a way of social sensing the emotions of others rather than just the
emotional experiences of users. These results show that, despite the
issues that social media have in terms of representativeness and
algorithmic confounding, the combination of advanced text analysis
methods with user demographic information in social media emotion
macroscopes can provide measures that are informative of the general
population beyond social media users.}, archiveprefix = {arXiv},
keywords = {Computer Science - Computers and Society,Computer Science -
Social and Information Networks}
} Copy to Clipboard
Social media generate data on human behaviour at large scales
and over long periods of time, posing a complementary approach
to traditional methods in the social sciences. Millions of texts
from social media can be processed with computational methods to
study emotions over time and across regions. However, recent
research has shown weak correlations between social media
emotions and affect questionnaires at the individual level and
between static regional aggregates of social media emotion and
subjective well-being at the population level, questioning the
validity of social media data to study emotions. Yet, to date,
no research has tested the validity of social media emotion
macroscopes to track the temporal evolution of emotions at the
level of a whole society. Here we present a pre-registered
prediction study that shows how gender-rescaled time series of
Twitter emotional expression at the national level substantially
correlate with aggregates of self-reported emotions in a weekly
representative survey in the United Kingdom. A follow-up
exploratory analysis shows a high prevalence of third-person
references in emotionally-charged tweets, indicating that social
media data provide a way of social sensing the emotions of
others rather than just the emotional experiences of users.
These results show that, despite the issues that social media
have in terms of representativeness and algorithmic confounding,
the combination of advanced text analysis methods with user
demographic information in social media emotion macroscopes can
provide measures that are informative of the general population
beyond social media users.
|
 |
Emotional reactions to robot colleagues in a role-playing
experiment
Nina Savela, Atte Oksanen, Max Pellert & David Garcia
International Journal of Information Management (2021)
[abs]
[cite]
[bibtex]
[link]
Savela, N., Oksanen, A., Pellert, M., & Garcia, D.
(2021). Emotional reactions to robot colleagues in a
role-playing experiment. International Journal of
Information Management, 60, 102361.
https://doi.org/10.1016/j.ijinfomgt.2021.102361
@article{savelaEmotionalReactionsRobot2021,
title = {Emotional reactions to robot colleagues in a role-playing
experiment}, volume = {60}, issn = {02684012}, url =
{https://linkinghub.elsevier.com/retrieve/pii/S0268401221000542}, doi =
{10.1016/j.ijinfomgt.2021.102361}, language = {en}, urldate =
{2021-05-27}, journal = {International Journal of Information
Management}, author = {Savela, Nina and Oksanen, Atte and Pellert, Max
and Garcia, David}, month = oct, year = {2021}, pages = {102361}
} Copy to Clipboard
We investigated how people react emotionally to working with
robots in three scenario-based role-playing survey experiments
collected in 2019 and 2020 from the United States (Study 1: N =
1003; Study 2: N = 969, Study 3: N = 1059). Participants were
randomly assigned to groups and asked to write a short post
about a scenario in which we manipulated the number of robot
teammates or the size of the social group (work team
vs. organization). Emotional content of the corpora was measured
using six sentiment analysis tools, and socio-demographic and
other factors were assessed through survey questions and LIWC
lexicons and further analyzed in Study 4. The results showed
that people are less enthusiastic about working with robots than
with humans. Our findings suggest these more negative reactions
stem from feelings of oddity in an unusual situationand the lack
of social interaction.
|
 |
Colexification Networks Encode Affective
Meaning
Anna Di Natale, Max Pellert and David Garcia
Affective Science (2021)
[abs]
[cite]
[bibtex]
[link]
@article{dinataleColexificationNetworksEncode2021,
title = {Colexification {Networks} {Encode} {Affective} {Meaning}}, issn
= {2662-2041, 2662-205X}, url =
{https://link.springer.com/10.1007/s42761-021-00033-1}, doi =
{10.1007/s42761-021-00033-1}, abstract = {Abstract Colexification is a
linguistic phenomenon that occurs when multiple concepts are expressed
in a language with the same word. Colexification patterns are frequently
used to estimate the meaning similarity between words, but the
hypothesis that these are related is still missing direct empirical
validation at scale. Here, we show for the first time that words linked
by colexification patterns capture similar affective meanings. Using
pre-existing translation data, we extend colexification databases to
cover much longer word lists. We achieve this with an unsupervised
method of affective lexicon extension that uses colexification network
data to interpolate the affective ratings of words that are not included
in the original lexicon. We find positive correlations between
network-based estimates and empirical affective ratings, which suggest
that colexification networks contain information related to affective
meanings. Finally, we compare our network method with state-of-the-art
machine learning, trained on a large corpus, and show that our simple
linguistics-informed unsupervised algorithm yields comparable
performance with high explainability. These results show that it is
possible to automatically expand affective norms lexica to cover
exhaustive word lists when additional data are available, such as in
colexification networks.}, language = {en}, urldate = {2021-05-17},
journal = {Affective Science}, author = {Di Natale, Anna and Pellert,
Max and Garcia, David}, month = may, year = {2021}
} Copy to Clipboard
Colexification is a linguistic phenomenon that occurs when
multiple concepts are expressed in a language with the same
word. Colexification patterns are frequently used to estimate
the meaning similarity between words, but the hypothesis that
these are related is still missing direct empirical validation
at scale. Here, we show for the first time that words linked by
colexification patterns capture similar affective meanings.
Using pre-existing translation data, we extend colexification
databases to cover much longer word lists. We achieve this with
an unsupervised method of affective lexicon extension that uses
colexification network data to interpolate the affective ratings
of words that are not included in the original lexicon. We find
positive correlations between network-based estimates and
empirical affective ratings, which suggest that colexification
networks contain information related to affective meanings.
Finally, we compare our network method with state-of-the-art
machine learning, trained on a large corpus, and show that our
simple linguistics-informed unsupervised algorithm yields
comparable performance with high explainability. These results
show that it is possible to automatically expand affective norms
lexica to cover exhaustive word lists when additional data are
available, such as in colexification networks.
|
 |
Social Media Data in Affective Science
Max Pellert, Simon Schweighofer and David Garcia
Handbook of Computational Social Science, Volume 1: Theory, Case
Studies and Ethics (2021)
[abs]
[cite]
[bibtex]
[link]
Pellert, M., Schweighofer, S., & Garcia, D. (2021).
Social Media Data in Affective Science. In U. Engel, A.
Quan-Haase, S. X. Liu, & L. Lyberg (Eds.), Handbook
of Computational Social Science, Volume 1: Theory, Case
Studies and Ethics (1st ed., pp. 240–255). Routledge.
https://doi.org/10.4324/9781003024583-18
@incollection{pellertSocialMediaData2021a,
title = {Social {{Media Data}} in {{Affective Science}}}, booktitle =
{Handbook of {{Computational Social Science}}, {{Volume}} 1: Theory,
{{Case Studies}} and {{Ethics}}}, author = {Pellert, Max and
Schweighofer, Simon and Garcia, David}, editor = {Engel, Uwe and
{Quan-Haase}, Anabel and Liu, Sunny Xun and Lyberg, Lars}, year =
{2021}, month = nov, series = {European {{Association}} of {{Methodology
Series}}}, edition = {First}, pages = {240–255}, publisher =
{{Routledge}}, address = {{London}}, doi = {10.4324/9781003024583-18},
abstract = {“The Handbook of Computational Social Science is a
comprehensive reference source for scholars across multiple disciplines.
It outlines key debates in the field, showcasing novel statistical
modeling and machine learning methods, and draws from specific case
studies to demonstrate the opportunities and challenges in CSS
approaches. The Handbook is divided into two volumes written by
outstanding, internationally renowned scholars in the field. This first
volume focuses on the scope of computational social science, ethics, and
case studies. It covers a range of key issues, including open science,
formal modeling, and the social and behavioral sciences. This volume
explores major debates, introduces digital trace data, reviews the
changing survey landscape, and presents novel examples of computational
social science research on sensing social interaction, social robots,
bots, sentiment, manipulation, and extremism in social media. The volume
not only makes major contributions to the consolidation of this growing
research field, but also encourages growth into new directions. With its
broad coverage of perspectives (theoretical, methodological,
computational), international scope, and interdisciplinary approach,
this important resource is integral reading for advanced undergraduates,
postgraduates and researchers engaging with computational methods across
the social sciences, as well as those within the scientific and
engineering sectors”–}, isbn = {978-1-00-302458-3}, langid = {english},
keywords = {Data processing,Mathematical models,Methodology,Social
sciences}
} Copy to Clipboard
The digital traces generated by social media offer the
opportunity to analyze human behavior at new scales, depths, and
resolutions. The results of analyses of social media data, while
sometimes difficult to generalize to a society as a whole, can
give important insights on detailed actions and subjective
states of individuals. This novel datasource offers a new window
to tackle research questions from Affective Science with respect
to emotion dynamics, collective emotions, and affective
expression in social contexts. In this chapter, we present a
balanced view of the benefits, risks, opportunities, and
pitfalls of analyzing affective life through social media data.
We review a variety of methods to quantify emotions and other
affective states from social media data. We illustrate the
application of these methods at new scales and resolutions in a
series of examples from previous research. We present research
gaps and open questions about the role, meaning, and
functionality of affective expression in social media, pointing
to emerging research trends in computational social science and
social psychology. When used critically and with robust research
methods, observational analyses of large-scale social media data
can be complementary to traditional methodologies in Psychology
and Cognitive Science.
|
 |
Dashboard of sentiment in Austrian social media during
COVID-19
Max Pellert, Jana Lasser, Hannah Metzler and David Garcia
Frontiers in Big Data (2020)
[abs]
[cite]
[bibtex]
[link]
@article{pellertDashboardSentimentAustrian2020a,
title = {Dashboard of {Sentiment} in {Austrian} {Social} {Media}
{During} {COVID}-19}, volume = {3}, issn = {2624-909X}, url =
{https://www.frontiersin.org/articles/10.3389/fdata.2020.00032/full},
doi = {10.3389/fdata.2020.00032}, abstract = {To track online emotional
expressions on social media platforms close to real-time during the
COVID-19 pandemic, we build a self-updating monitor of emotion dynamics
using digital traces from three different data sources in Austria. This
enables decision makers and the interested public to assess dynamics of
sentiment online during the pandemic. We use web scraping and API access
to retrieve data from the news platform derstandard.at, Twitter and a
chat platform for students. We document the technical details of our
workflow in order to provide materials for other researchers interested
in building a similar tool for different contexts. Automated text
analysis allows us to highlight changes of language use during COVID-19
in comparison to a neutral baseline. We use special word clouds to
visualize that overall difference. Longitudinally, our time series show
spikes in anxiety that can be linked to several events and media
reporting. Additionally, we find a marked decrease in anger. The changes
last for remarkably long periods of time (up to 12 weeks). We discuss
these and more patterns and connect them to the emergence of collective
emotions. The interactive dashboard showcasing our data is available
online at http://www.mpellert.at/covid19_monitor_austria/. Our work is
part of an web archive of resources on COVID-19 collected by the
Austrian National Library.}, language = {English}, urldate =
{2020-10-27}, journal = {Frontiers in Big Data}, author = {Pellert, Max
and Lasser, Jana and Metzler, Hannah and Garcia, David}, year = {2020},
note = {Publisher: Frontiers}, keywords = {Affective sciences,
Collective emotions, COVID-19, Dashboard, Digital traces, Real-time
monitoring, Social Media, Webscraping}
} Copy to Clipboard
To track online emotional expressions on social media platforms
close to real-time during the COVID-19 pandemic, we build a
self-updating monitor of emotion dynamics using digital traces
from three different data sources in Austria. This enables
decision makers and the interested public to assess dynamics of
sentiment online during the pandemic. We use web scraping and
API access to retrieve data from the news platform
derstandard.at, Twitter and a chat platform for students. We
document the technical details of our workflow in order to
provide materials for other researchers interested in building a
similar tool for different contexts. Automated text analysis
allows us to highlight changes of language use during COVID-19
in comparison to a neutral baseline. We use special word clouds
to visualize that overall difference. Longitudinally, our time
series show spikes in anxiety that can be linked to several
events and media reporting. Additionally, we find a marked
decrease in anger. The changes last for remarkably long periods
of time (up to 12 weeks). We discuss these and more patterns and
connect them to the emergence of collective emotions. The
interactive dashboard showcasing our data is available online at
http://www.mpellert.at/covid19_monitor_austria/. Our work is
part of an web archive of resources on COVID-19 collected by the
Austrian National Library.
|
 |
The individual dynamics of affective expression on social
media
Max Pellert, Simon Schweighofer & David Garcia
EPJ Data Science (2020)
[abs]
[cite]
[bibtex]
[link]
@article{pellertIndividualDynamicsAffective2020,
title = {The individual dynamics of affective expression on social
media}, volume = {9}, issn = {2193-1127}, url =
{https://epjdatascience.springeropen.com/articles/10.1140/epjds/s13688-019-0219-3},
doi = {10.1140/epjds/s13688-019-0219-3}, language = {en}, number = {1},
urldate = {2020-01-13}, journal = {EPJ Data Science}, author = {Pellert,
Max and Schweighofer, Simon and Garcia, David}, month = dec, year =
{2020}, pages = {1}
} Copy to Clipboard
Understanding the temporal dynamics of affect is crucial for our
understanding human emotions in general. In this study, we
empirically test a computational model of affective dynamics by
analyzing a large-scale dataset of Facebook status updates using
text analysis techniques. Our analyses support the central
assumptions of our model: After stimulation, affective states,
quantified as valence and arousal, exponentially return to an
individual-specific baseline. On average, this baseline is at a
slightly positive valence value and at a moderate arousal point
below the midpoint. Furthermore, affective expression, in this
case posting a status update on Facebook, immediately pushes
arousal and valence towards the baseline by a proportional
value. These results are robust to the choice of the text
analysis technique and illustrate the fast timescale of
affective dynamics through social media text. These outcomes are
of high relevance for affective computing, the detection and
modeling of collective emotions, the refinement of psychological
research methodology, and the detection of abnormal, and
potentially pathological, individual affect dynamics.
|
 |
Inference to the Best Explanation in Uncertain Evidential
Situations
Borut Trpin and Max Pellert
The British Journal for the Philosophy of Science (2018)
[abs]
[cite]
[bibtex]
[link]
Trpin, B., & Pellert, M. (2018). Inference to the
Best Explanation in Uncertain Evidential Situations.
The British Journal for the Philosophy of
Science.
https://doi.org/10.1093/bjps/axy027
@article{trpin_inference_2018, title =
{Inference to the Best Explanation in Uncertain Evidential Situations},
issn = {0007-0882, 1464-3537}, url =
{https://academic.oup.com/bjps/advance-article/doi/10.1093/bjps/axy027/4935150},
doi = {10.1093/bjps/axy027}, journaltitle = {The British Journal for the
Philosophy of Science}, author = {Trpin, Borut and Pellert, Max},
urldate = {2018-03-19}, date = {2018-03-14}, langid = {english}
} Copy to Clipboard
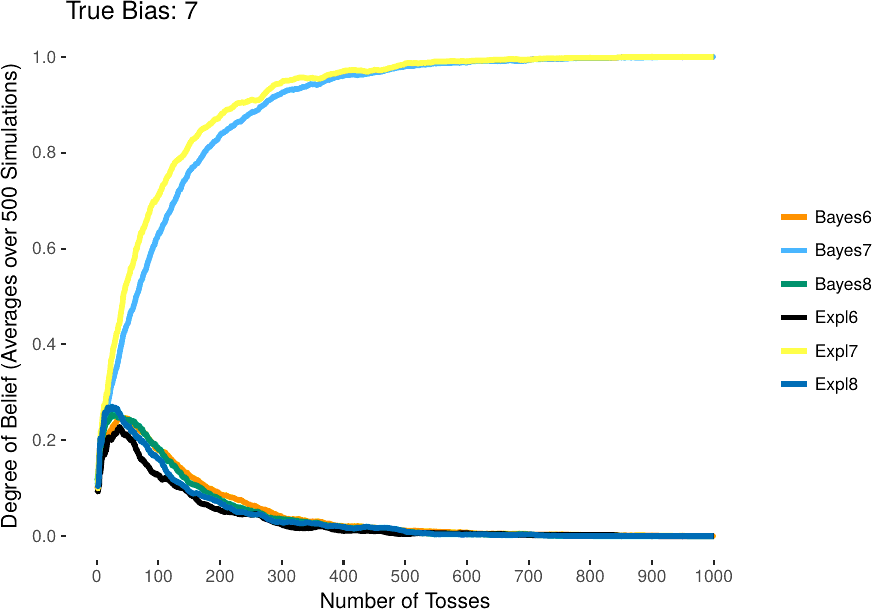
It has recently been argued that a non-Bayesian probabilistic
version of inference to the best explanation (IBE*) has a number
of advantages over Bayesian conditionalization (Douven [2013];
Douven and Wenmackers [2017]). We investigate how IBE* could be
generalized to uncertain evidential situations and formulate a
novel updating rule IBE**. We then inspect how it performs in
comparison to its Bayesian counterpart, Jeffrey
conditionalization (JC), in a number of simulations where two
agents, each updating by IBE** and JC, respectively, try to
detect the bias of a coin while they are only partially certain
what side the coin landed on. We show that IBE** more often
prescribes high probability to the actual bias than JC. We also
show that this happens considerably faster, that IBE** passes
higher thresholds for high probability, and that it in general
leads to more accurate probability distributions than JC.
References
Douven, I. [2013]: ‘Inference to the Best
Explanation, Dutch Books, and Inaccuracy Minimisation’,
Philosophical Quarterly, 63(252), pp. 428–44.
Douven,
I. and Wenmackers, S. [2017]: ‘Inference to the Best Explanation
versus Bayes’s Rule in a Social Setting’, The British Journal
for the Philosophy of Science, 68(2), pp. 535–70.
|
 |
Collective Dynamics of Multi-Agent Networks: Simulation
Studies in Probabilistic Reasoning
Max Pellert
Proceedings of the MEi: CogSci Conference 2017 (2017)
[abs]
[cite]
[bibtex]
[link]
Pellert, M. (2017). Collective Dynamics of
Multi-Agent Networks: Simulation Studies in
Probabilistic Reasoning. In P. Hochenauer, C. Schreiber,
K. Rötzer, & E. Zimmermann (Eds.), Proceedings of
the MEi: CogSci Conference 2017. Budapest, Hungary:
Comenius University in Bratislava, Slovakia.
@inproceedings{pellert2017, location =
{{Budapest, Hungary}}, title = {Collective {{Dynamics}} of
{{Multi}}-{{Agent Networks}}: {{Simulation Studies}} in {{Probabilistic
Reasoning}}}, isbn = {978-80-223-4325-1}, timestamp =
{2017-12-02T18:48:08Z}, booktitle = {Proceedings of the {{MEi}}:
{{CogSci Conference}} 2017}, publisher = {{Comenius University in
Bratislava, Slovakia}}, author = {Pellert, Max}, editor = {Hochenauer,
P. and Schreiber, C. and Rötzer, Katharina and Zimmermann, Elisabeth},
editorb = {Farkas, I.}, editorbtype = {redactor}, date = {2017-06}
} Copy to Clipboard
Agent-based modelling is seen as an alternative to traditional,
“equation-based” modelling. It has seen applications in diverse
areas. At the same time, the modern formulation of network
theory became part of science, influencing discipline after
discipline. Historically, however, networks have almost
exclusively been dealt with implicitly by agent-based modellers.
Their “network awareness” is a very recent phenomenon [1].
Belief updating refers to the process that enables an agent to
alter his belief in a given hypothesis conditional on evidence
that it receives. This concept is part of the field of “formal
epistemology” that explores knowledge and reasoning using tools
from math and logic. Bayesian approaches to probabilistic
reasoning are dominant here. Proponents uphold that Bayesianism
is the only rational way of belief formation, given that no
other strategy protects an agent in principle from “Dutch books”
(bets that guarantee a loss to one side). Nonetheless,
alternatives that are probabilistic but not (Standard-)Bayesian
have been introduced under the heading of “Inference to the Best
Explanation”. The use of alternatives is justified by
questioning the practical relevance of Dutch book arguments and
by resorting to pragmatism: It has been shown that there are
strategies that have speed and accuracy advantages in belief
updating [2].
This thesis will explore different scenarios with multiple
agents updating their beliefs and influencing each other through
specific network structures. The dynamics on networks as well as
the dynamics of networks will therefore be in the focus of
analysis [3]. Agent behavior and network dynamics develop
interdependently, i.e. they coevolve.
Apart from being a methodological advance, it is expected that
this approach can yield novel theoretical insights on the
dynamical formation of network structures by interacting agents.
Additionally, it will be possible to demonstrate that there are
alternatives to Bayesian updating that also yield advantages in
multi-agent settings. On a meta-theoretical level it will be
argued that simulation results can be treated as
quasi-empirical. Several necessary conditions will be identified
that need to be fulfilled for this aim.
We borrow methods
from computer science to investigate questions from philosophy
(of science). Additionally, work done in the social sciences on
agents and networks will provide input.
References
[1] M. Newman, Networks: An Introduction.
New York, NY, USA: Oxford University Press, Inc., 2010.
[2]
I. Douven and S. Wenmackers, “Inference to the Best Explanation
versus Bayes’s Rule in a Social Setting,” The British Journal
for the Philosophy of Science, 2015.
[3] A. Namatame and
S.-H. Chen, Agent-Based Modeling and Network Dynamics. Oxford,
New York: Oxford University Press, p.10, 2016.
|
 |
Are Heterogeneous Expectations a Viable Alternative to
Rational Expectations in Economics?
Max Pellert
Proceedings of the MEi: CogSci Conference 2016 (2016)
[abs]
[cite]
[bibtex]
[link]
Pellert, M. (2016). Are Heterogeneous Expectations a
Viable Alternative to Rational Expectations in
Economics? In S. Ersoy, P. Hochenauer, & C.
Schreiber (Eds.), Proceedings of the MEi: CogSci
Conference 2016. Vienna, Austria: Comenius
University in Bratislava, Slovakia.
@inproceedings{pellert2016, location =
{{Vienna, Austria}}, title = {Are {{Heterogeneous Expectations}} a
{{Viable Alternative}} to {{Rational Expectations}} in {{Economics}}?},
isbn = {978-80-223-4137-0}, timestamp = {2017-07-24T16:54:42Z},
booktitle = {Proceedings of the {{MEi}}: {{CogSci Conference}} 2016},
publisher = {{Comenius University in Bratislava, Slovakia}}, author =
{Pellert, Max}, editor = {Ersoy, S. and Hochenauer, P. and Schreiber,
C.}, editorb = {Farkas, I.}, editorbtype = {redactor}, date = {2016}
} Copy to Clipboard
Expectations play a crucial role in economic theories. Different
ways of modelling and parameterising expectations change
outcomes massively in (macro-)economic models. On a
meta-theoretical level, some authors even go as far as to claim
that: “Individual expectations about future aggregate outcomes
are the key feature that distinguishes social sciences and
economics from the natural sciences” [1].
The prevailing expectation hypothesis used in economics is that
of “rational expectations” (RE) [2]. Here, it is assumed that
expectations are nothing more than the predictions of the
relevant theory, i.e., they are defined to be model-consistent.
Furthermore, it is assumed that people make no systematic
mistakes. Finally, modellers typically introduce “representative
agents” (e.g., “the average household”) equipped with RE to
bridge the gap between micro- and macro-levels; all interacting
units of the economy are therefore alike. Over time, it became
more and more evident that certain real-world phenomena, like
the global financial crisis, are very hard to fit in a uniform
RE framework.
Expectations modelling in economic theory thus is in need of
theoretical innovation. New proposals ought to have a strong
interdisciplinary foundation, reconciling valuable insights from
several other disciplines, including sociology, psychology and
anthropology. In particular, we take interdisciplinary thinking
to be an effective remedy against the harmful tendency of a
large part of economics to isolate specific aspects of human
behaviour and then to treat these and only these as “purely”
economic subject matter, as in the case of RE.
The concept of “heterogeneous expectations” has been suggested
as an alternative to RE, instantiated in so-called “agent-based
models” [3]. Here, heterogeneous agents use different methods of
expectation formation. The “wilderness” of this approach is
fenced in e.g. by the use of genetic algorithms that describe
agents' switching between heuristics according to a fitness
criterion, e.g. accuracy of prediction.
The goal of our project is to give a critical assessment of
rewarding ends and eventual dead ends in the theoretical
development of agent-based economic modelling with heterogeneous
expectations. The outcome of this work should be a stepping
stone towards a more outward-looking theory of dynamics in
(financial) markets.
Acknowledgments
Special thanks to Paolo Petta and OFAI
for supporting this project.
References
[1] C. Hommes, “The heterogeneous
expectations hypothesis: Some evidence from the lab,” Journal of
Economic Dynamics and Control, vol. 35, no. 1, 2011,
pp.1.
[2] J. F. Muth, “Rational Expectations and the Theory
of Price Movements,” Econometrica, vol. 29, no. 3, pp. 315–335,
1961.
[3] D. Delli Gatti, S. Desiderio, E. Gaffeo, P. Cirillo
and M. Gallegati, Macroeconomics from the Bottom-up. Milan,
Italy: Springer Italia, 2011.
|